How to Build a Streaming Text To Audio Service with StyleTTS2
In the digital age, content consumption habits have rapidly evolved, with a significant shift toward audio formats. Audiobooks, podcasts, and voice interfaces are now integral parts of our daily lives. Catering to this demand, creating a service that converts text to audio seamlessly is not just innovative but essential. Enter StyleTTS2, the cutting-edge text-to-speech (TTS) technology, which presents a unique opportunity to develop a streaming text-to-audio service that stands out. This article delves into the steps required to construct such a service, emphasizing the synthesis engine’s capabilities and how to harness them for a captivating auditory experience.
How can this be Used?
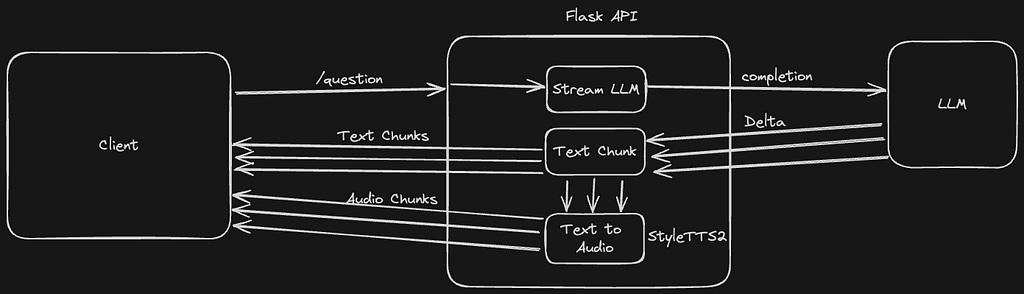
Lets talk about what we are building and how it can be used. The goal for this build is to create a high-performance text-to-audio service that can be customized to produce any voice you choose. My choice to make this walkthrough streaming is to ensure this solution will work with the latest generative AI apps. When working with generative AI, we can stream the response text as its being generated, and also stream the audio as the text is being generated to produce a seamless user experience. The audio and text will start to stream almost instantly, creating a more natural conversation experience that users will love. I imagine this service could be used in automated phone call assistants and chat apps.
The Build
First, let’s create a backend server to handle the text-to-audio general requests and then build an audio chat example.
Create a requirements.txt file and get our dependencies installed
styletts2
flask
openai==0.28
Next, let’s get a basic Flask web server running to serve our web page and handle our API requests.
from flask import Flask, request, Response
app = Flask(__name__)
if __name__ == '__main__':
app.run()
Then, create two endpoints, one for serving our web page and another for handling AI chat completion. We will be using the mimeType value of text/event-stream to let our client know, the response will be streamed back. Inside our stream() function will be using yield to return chunks of data as we generate them.
@app.route("/")
def hello():
return ''
@app.route('/question')
def askQuestion():
def stream():
pass
return Response(stream(), mimetype='text/event-stream')Next, lets configure our text-to-speech method to make it easily called with a simple string argument.
from styletts2 import tts
SAMPLE_RATE = 24000
tts = tts.StyleTTS2()
def textToSpeech(text):
voicewave = tts.inference(text, diffusion_steps=3, output_sample_rate=SAMPLE_RATE)
return voicewave
We can also pass another parameter here target_voice_path here to pass the target voice wav file we want for emulate for our output.
Our output from StyleTTS2 is going to be innumpy.ndarry wav audio data. To send the audio over the network, we want to convert it to base64 format. This will give us a format we can easily play on any device.
import base64
from scipy.io.wavfile import write
def ndarrayToBase64(arr):
bytes_wav = bytes()
byte_io = io.BytesIO(bytes_wav)
write(byte_io, SAMPLE_RATE, arr)
wav_bytes = byte_io.read()
audio_data = base64.b64encode(wav_bytes).decode('UTF-8')
return audio_data
Now, we will configure our streaming audio endpoint askQuestion() to generate answers, generate voice, and stream those back to the client.
import openai
CHAR_BUFFER_LEN = 100
def generateAudioSseEvent(text):
if not text:
return 'data: %s\n\n' % json.dumps({"text": ""})
audio = ndarrayToBase64(textToSpeech(text))
return 'data: %s\n\n' % json.dumps({"audio": audio})
@app.route('/question')
def askQuestion():
args = request.args
question = args.get('question', 'How far is the moon from mars?')
def stream():
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": question}],
stream=True,
)
buff = ''
for chunk in res:
if len(chunk.choices[0]) and chunk.choices[0].delta and chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
yield 'data: %s\n\n' % json.dumps({"text": content})
if len(chunk.choices[0]) and chunk.choices[0].delta and chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
buff += content
# Try to keep sentences together, making the voice flow smooth
last_delimiter_index = max(buff.rfind(p) for p in end_of_sentence_punctuation)
if last_delimiter_index == -1 and len(buff) < CHAR_BUFFER_LEN:
continue
current = buff[:last_delimiter_index + 1]
buff = buff[last_delimiter_index + 1:]
yield generateAudioSseEvent(current)
yield generateAudioSseEvent(buff)
yield 'data: %s\n\n' % json.dumps({"text": "", "audio": "", "done": True})
return Response(stream(), mimetype='text/event-stream')
Next, we can create our web page to test everything out. In this step we will create an inline web page, but you could also save this into your templates folder and render the html as a template. I wanted everything to fit into one file so I could easily copy to colab for GPU performance testing.
@app.route("/")
def hello():
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Realtime Text->Audio Generator</title>
</head>
<body>
<input type="text" id="inputField" placeholder="Enter question here">
<button onclick="sendMessage()">Send</button>
<div id="result"></div>
<script>
var audioQueue = []
var playing = false;
const audioElement = new Audio();
var currentIndex = 0;
function playNextAudio() {
if (currentIndex < audioQueue.length) {
audioElement.src = audioQueue[currentIndex];
audioElement.play();
currentIndex++;
audioElement.onended = function() {
playNextAudio();
};
} else {
playing = false;
}
}
function sendMessage() {
var inputValue = document.getElementById('inputField').value;
const queryString = '?question=' + encodeURIComponent(inputValue)
var eventSource = new EventSource('/question' + queryString)
eventSource.onmessage = function(event) {
var message = JSON.parse(event.data);
if (message.done) {
console.log('Closing session')
eventSource.close()
}
if (message.text) {
document.getElementById("result").innerHTML += message.text;
}
if (message.audio) {
audioQueue.push("data:audio/wav;base64," + message.audio)
if (!playing) {
playing = true;
playNextAudio()
}
}
console.log('Message: ' + message.text);
};
}
</script>
</body>
</html>
"""
return htmlConsiderations
- This model is not optimized for Apple Silicon (MPS) yet so it was quite slow when testing (5–6 seconds for small text) on my laptop. This model must be run on a GPU or TPU to get a production quality latency required to make this usable. When running on T4 GPU, I was able to get 500ms latency, which I think is reasonable for a sentence of audio.
- Once the first audio chunk has been returned, the pressure for low latency is mostly alleviated. While the first audio chunk plays, we can queue the proceeding chunks to play in order.
Thanks for reading, happy coding!
References
- StyleTTS2 Model https://github.com/yl4579/StyleTTS2
- Python library https://github.com/sidharthrajaram/StyleTTS2